

How to approach project management when the project is data?
Introduction
In most companies, the architecture of project management instruments usually revolves around elements like tasks, milestones, and timelines. These tools, though very effective in delivering software products or handling general business operations, somehow lag in reflecting the specifics that make data projects different.
Data project management challenges
Compositions ban not only refer to tasks but also talk about flows. The fact is, data fades away from the mixed sources through several layers like transformation, modeling, and quality control before it is delivered to a business user. This way, the data gear "learns" definitions, assumptions, and ownership. So to "manage" a data project really means to manage the data lineage, the documentation for every piece of the data, and the governance structures for the compliance and trust assurance.
My impression is that many teams piece this together using different tools. Miro might show architecture at a very abstract level, Jira will be used to keep track of implementation tasks, Confluence or Notion will be utilized for storing definitions, and spreadsheets will be holding Indicators. Such fragmentation always leads to the same problem: The map of the organization is out of sync with the territory. The diagrams are not updated when pipelines change. The glossaries do not match the metrics that are in production. Documentation turns from a place where half-done pages coexist to a graveyard. Compliance inspections become detective work.
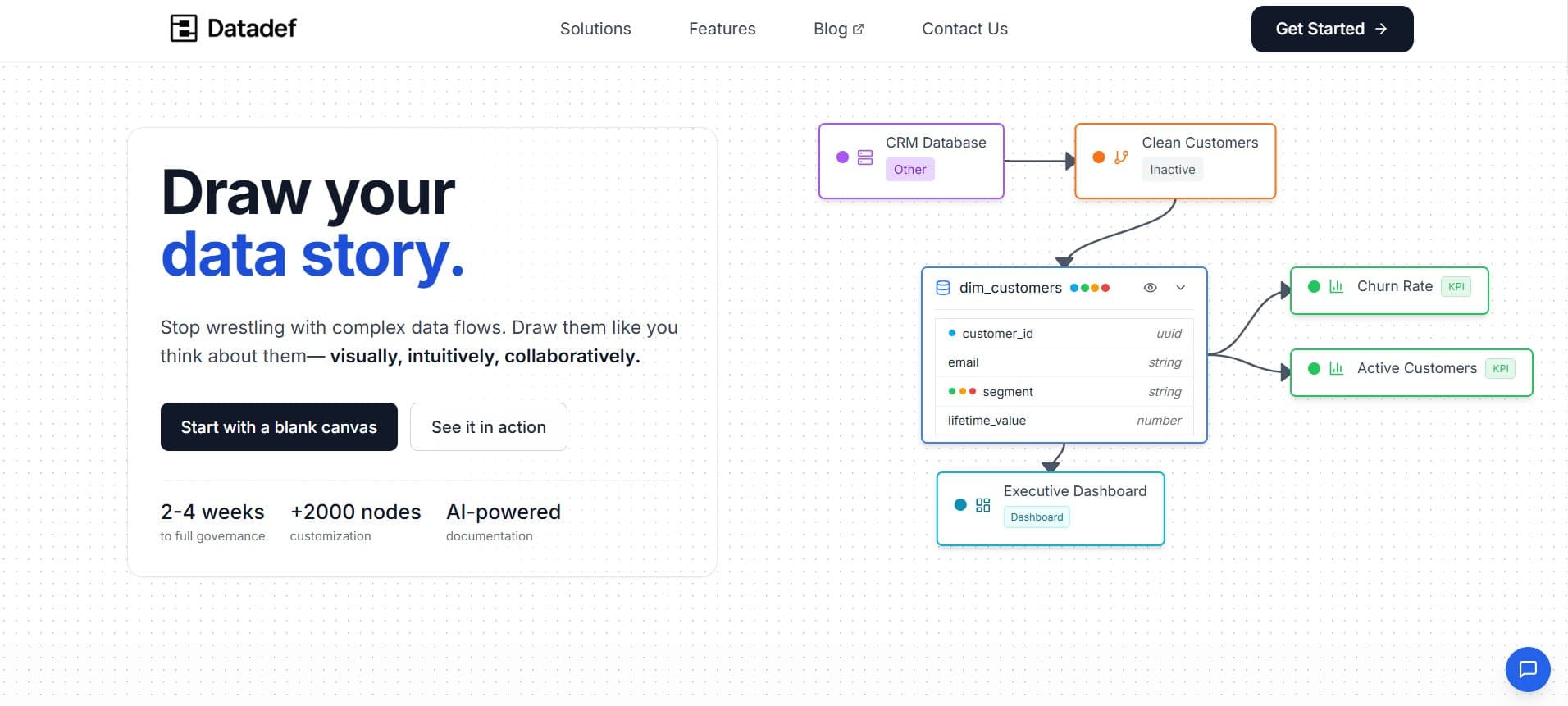
With Datadef.io, I am trying to bridge such a gulf. The objective is to connect the three - diagrams, glossaries, and documentation - instead of keeping them fundamentally different. A canvas is the core analogy: the teams can show the data they have in the way that matches the origin, changes, and destination. But it is not like a pure whiteboard - every object on the canvas is deep. Once a table, an indicator, or a connection is described, then it can be used without the need for further description throughout the glossary, documentation, and project inventory. In case of any change, the change will be communicated.
Document is the second level. Since each element of a diagram is associated with metadata, the documentation of the project, no matter if it is a wiki, a PDF, or a Word file, can be automatically generated. Here, the headache of "keeping documentation up to date" turns into a resolved issue: documentation is not a parallel activity anymore, it is simply a byproduct of the project work. The assistance of AI makes raw descriptions done by the team into user-friendly narrative documents cutting down the description time for stakeholders.
Eventually, governance is a part of the design rather than an afterthought. The features of ownership, quality, rules, examples, and compliance can be among those that are connected to objects. It is, therefore, that an audit or an ISO inspection can use the very same knowledge base that the team accesses for development.
Practical application and comparaison with other solutions
A common case can be a team working on a pipeline that is the data source for a Power BI dashboard. Instead of the team going through stages like describing the architecture in Miro, defining indicators in Excel, and writing a Word document for compliance, they can open the canvas and map the complete flow there, mark each element with definitions and responsibilities, and let the system make consistent documentation across all outputs. The organization acts upon the definitions that are the same for all and governance is no longer a property of the workflow at a later stage but occurs simultaneously with it.
Some people tend to rely on extremely complicated solutions like Collibra or Informatica which, albeit being very powerful, are, most of the time, too cumbersome for small teams. Others are using generalist tools like Confluence, Notion, Jira, and Miro, which are characterized by being quite agile but hardly synchronized or specially tailored for data lineage. An overwhelming majority of people if not all resorting to workarounds of combining spreadsheets, diagrams, and texts are there as well.
Conclusion
In short, the way most organizations handle data projects today is fragmented: architecture lives in one place, definitions in another, and documentation somewhere else entirely. This separation creates friction, slows down collaboration, and undermines trust in the data itself. What I am building with Datadef.io is an attempt to unify those layers—lineage, documentation, and governance—into a single, living workspace where change in one place reflects everywhere.
The project is still young, but I believe the foundation is solid enough to be useful already. If you have faced the same pain points—out-of-date diagrams, scattered glossaries, compliance reviews that feel like detective work—I would love for you to try it, challenge it, and tell me what works or doesn’t. Datadef is not meant to replace all your tools, but to give data teams a space designed specifically for the realities of managing complex data projects.
You can explore it here: Datadef.io.



